
We will take a look at some of the practical applications of the machine intelligence capabilities discussed in Part 1 of this series, and consider the business opportunities created by this new movement.
Part 2 of 3 – New Terrains for Businesses
In Part 1 of this paper we looked briefly at what machine learning and deep learning mean and how these programming techniques have enabled computers to “see” and “hear”, to understand and communicate with humans in natural languages, to find patterns in big data and make decisions based on them. In this Part 2, we will look in a little more detail at some of the practical applications of those machine intelligence capabilities and consider the business opportunities created by this new movement.
For a start, we need the AI-enablers, those that make AI technologies accessible by providing the hardware and software building blocks and tools. Then, there are a myriad of opportunities for those who can use those tools to create the practical applications that will bring AI out of research labs and into our homes, offices, hospitals and factories.
AI Enablers – Hardware Makers
On the hardware side, training deep neural networks takes immense amounts of computation and requires powerful processors. For instance, Baidu, a leading Chinese tech company, said that training one of its speech recognition models takes 4 terabytes of data and 20 billion billion maths operations! This makes graphics processing units (GPUs), a type of processor originally developed for video gaming that is particularly effective at handling parallel operations, a natural fit for deep learning. In simplistic terms, the central processing unit (CPU), which is the brain in all PCs, laptops, servers and smartphones, consists of several cores (e.g. four or eight in a typical Intel CPU for PCs, up to 22 in Intel’s Xeon chips for data centres and supercomputers). A CPU breaks each task into a series of instructions and executes them sequentially one or several at a time. GPUs, on the other hand, consist of hundreds or thousands of smaller cores that are configured to execute numerous instructions concurrently. Where high performance computing is needed, whether it is for video games, big data analytics or deep learning, GPUs are usually added as an “accelerator” to supplement the CPU.
Nvidia, the world’s leading GPU developer, has thus been a huge winner over the past five years. In 2011, a group of AI researchers found that 12 Nvidia GPUs were able to match the performance of 2,000 CPUs when used to train certain neural networks,[1] reducing training time from weeks to days, even hours. The company has since been both capitalising on and investing in deep learning to extend its lead in the high performance computing and accelerator space. Its latest model of GPU accelerator for data centres, the Tesla P100, contains 3584 cores and uses a new proprietary architecture (dubbed “Pascal”) that is optimised for deep learning. Nvidia also recently unveiled its first so-called “AI supercomputer”. Containing eight Tesla P100 GPUs with a combined 28672 cores, the DGX-1 can train neural networks 75 times faster than CPUs and deliver the performance of 250 conventional servers.
One of the drivers for chip innovation comes from the different needs of the training phase and the inference phase of deep learning. As briefly explained in Part 1 of this paper, putting deep neural networks to work first requires the algorithmic model to be trained using large existing datasets. When a trained model is put to use (e.g. to detect patterns or make predictions based on new data), it does so by making “inferences”. The key to optimising training is higher throughout, i.e. the number of instructions executed per second. The key to optimising inference is lower latency, which is the “wait time” between input of user command and the processor’s delivery of output. While GPUs’ parallel architecture makes them naturally efficient at training, they have not always had the upper hand in inference due to the delay in dataflow between CPU and GPU and between GPUs. Nvidia is trying to solve this drawback through an interconnect mechanism called NVLink (used in Tesla P100 and DGX-1), which allows CPU-GPU and GPU-GPU data sharing to reduce latency. Others are bypassing GPUs altogether and are developing specialised AI processors that combine the CPU and the accelerator.
Nervana, a two year old start-up, is crafting a new chip with all the architectural elements designed specifically for running deep learning algorithms. It is said to “include everything needed for deep learning and nothing more”.[2] Known as the Nervana Engine, the chip is reportedly capable of delivering 10 times the performance by Nvidia’s Maxwell architecture GPUs and up to 5 or 6 times that of Nvidia’s new Pascal architecture,[3] though that is yet to be verified by third party experts. Nervana’s new chip is yet to be released to market, but the company itself was acquired in August by Intel as the world’s largest chip-maker sought to boost its capability to supply the steam engines of an AI-powered future. While Intel has been largely absent from the GPU market, its Xeon Phi processors, which use the CPU (containing up to 72 cores) to perform both serial and parallel processing steps, are an alternative high-end accelerator offering to Nvidia’s Tesla products.
Meanwhile Google has created its own purpose-built AI processors, known as Tensor Processing Units (TPUs). Google has not stated any plan to commercialise TPUs, but has been using them to power TensorFlow, the open source machine learning framework which runs the deep learning algorithms behind a range of Google’s products and services, such as search ranking, Street View and Google Now, as well as the famous AlphaGo. A similar AI-centric thinking also led US start-up, Wave Computing, to develop a chip called Dataflow Processing Unit (DPU). The Wave DPU is said to be optimised for supporting dataflow model based deep learning frameworks (such as TensorFlow) through its 16,000+ parallel processing elements, massive memory bandwidth and shared memory architecture. It is reportedly capable of training deep neural networks at more than 25 times the speed of some GPUs.[4]


A TPU board; Server racks with TPUs used in the AlphaGo matches with Lee Sedol. Source: Google
Also exploring new dataflow architecture is KnuPath, the hardware arm of the KnuEdge group of innovation companies founded by former NASA Administrator, Dan Goldin. Inspired by the same neurologically-based concept as neuromorphic computing (see below), the architecture of KnuPath’s Hermosa Processor emphasises low communication and memory latency and parallel processing so as to achieve scalability and speed. It is suited for machine learning generally and digital signal processing (e.g. sound and image) more specifically. Compared to conventional GPUs, The Hermosa Processor is 2.5 times faster and delivers 44 times more frames per second in video processing (which gives a resolution difference of 5 mega-pixels versus 2 mega pixels).[5]
Rather than to custom-build processors to suit machine learning, which can be very expensive, it is also possible to custom-program certain types of processors to suit specific kinds of computational tasks, including machine learning. One type of such reprogrammable processor is known as a field programmable gate array (FPGA). Microsoft has decided to make FPGAs the backbone of its Bing online search engine and its Azure cloud platform, as well as to power some of its machine learning related research and services. Programing chips is difficult and FPGAs may not be able to match some purpose-built chips in speed, but FPGAs can be reprogramed to suit different neural network models, which afford flexibility and can save significant costs in the long run. DeePhi, a Chinese start-up, has developed two FPGA-based deep learning accelerator architectures for different types of algorithms, which are, according to the company, faster and more energy-efficient than GPUs. As research on AI accelerates and expands, companies that specialise in developing FPGAs, such as Xilinx and Altera (which was acquired by Intel last year), may see a rise in demand for their products.
Beyond Binary, von Neumann and Silicon
More radically new technology may also be awaiting us in the not-too-distant future as scientists push the boundaries of physics beyond Moore’s Law (which is the famous observation and prediction made by Intel co-founder Gordon Moore in 1965, that the number of transistors on a chip – hence the processing power – would double every two years). An area to watch is neuromorphic computing, which models the computational process of silicon chips on the biological brain with its billions of neurons and trillions of synapses (neural connections). (It should be clarified that neuromorphic chips work differently from the software-based deep neural networks discussed throughout this paper, but share strengths in similar area, e.g. visual, audio and other cognitive functions.) In the von Neumann architecture, which is used in the vast majority of today’s computers, bits of data are shuttled back and forth between the separate chip modules for input/output, central processing, and memory in linear sequences. Neuromorphic architecture, by contrast, facilitates massively parallel processing (like the way data is processed throughout the neural networks of a human brain) and integrates computation, communications and memory, which makes it better suited for tasks that require versatility, such as pattern recognition and processing of sensory data. Neuromorphic chips also use far less power.
A growing number of companies are investing in neuromorphic computing. IBM recently unveiled its magnificent second generation TrueNorth, a neuro chip containing 4096 cores, 1 million programmable neurons and 256 million synapses, though at present it is used to power IBM’s own cognitive computing services only. General Vision, on the other hand, has commercialised its relatively humble CM1K neuro chip (with 1024 neurons, though expandable to 9216 neurons by adding expansion modules) at fairly affordable prices (ranging from just US$275 to several thousand dollar). The company also licenses the underlying architecture, called NeuroMem, for integration into FPGAs and other specialised chips.
Qualcomm, the company best known for its smartphone chips, has been incubating a brain-inspired Neural Processing Unit (NPU) for some time, but has not released it as part of its Snapdragon 820 smartphone processor as anticipated. The company is instead making machine learning available on mobile devices by offering a software development kit (SDK) known as the Qualcomm Snapdragon Neural Processing Engine. This SDK is powered by Qualcomm’s Zeroth software platform, and allows device makers to run their own neural network models locally on any Snapdragon 820-powered smartphones, security cameras, cars or drones, so as to enable cognitive functions like scene detection, face recognition and object avoidance on those devices even without connection to the cloud.
Looking further afield, silicon is also no longer the limit. An IBM research team recently succeeded in creating artificial neurons using a “phase-change material” named germanium antimony telluride. These faux neurons behave similarly to the real thing both in how their physical state changes when electricity passes through them and in their stochastic behaviour.
Elsewhere much research is being done in quantum computing, technology that runs computations using quantum mechanics-based “qubits” instead of transistor-based binary digits. Quantum computing holds the promise to achieve super speed for certain types of calculations and to solve problems with hitherto unsolvable complexity. There is potential for machine learning to take a “quantum” leap.
Machine Learning Framework and Toolkit Providers
On the software side, machine learning frameworks have become widely and freely available over the past year. Most major tech companies active in AI research (Google, Microsoft, IBM, Amazon and Facebook) have open sourced parts of their neural network algorithms to encourage the developer community to experiment with applications. Anyone writing a smartphone app can now incorporate voice interface through TensorFlow either by training models with their own data using Google’s language parsing algorithms (SyntaxNet) or by incorporating models pre-trained by Google (so far available in some 40 languages). Similarly, everyone is free to use Microsoft’s Distributed Machine Learning Toolkit (DMLT) and Computational Network Toolkit (CNTK) to build their own machine vision models, whether you are creating an app to analyse MRI scans or writing code for drones.
These frameworks also support distributed computing, meaning that users can train their models across multiple PCs and servers in parallel and combine their processing power to speed up the training process and incorporate bigger datasets. This makes deep learning even more accessible to individuals and start-ups without the resources of powerful data centres or custom-made TPUs, and provides what technologists call scalability (the ability to run the same algorithm across multiple machines). An inspiring example is tech entrepreneur George Hotz, founder of start-up Comma.ai, who has built an entire autonomous driving system in his garage using open source toolkits.
Before TensorFlow and DMLT were unveiled in November 2015, a number of community-maintained open source machine learning frameworks were already popular among researchers (e.g. Theano, Caffe, Torch – AlphaGo was originally developed on Torch7). However, Google’s and Microsoft’s move to open source of their production-quality machine learning toolkits, which power many of their own popular products, signalled a pivoting point in how far machine learning techniques have matured and are ready for mainstream commercial deployment. Tens of thousands of developers have taken up TensorFlow within just several months of its release.
Nervana also recently open sourced its deep learning framework, Neon, while offering its proprietary library of pre-trained models to paid users on its cloud platform. Although Neon may deliver superior performance than many competitor products,[6] it remains less known. Becoming part of Intel, open sourcing its code, and the upcoming release of its specialist chip, the Nervana Engine, may change that.
Applied Machine Learning-as-a-Service
It is truly exciting for software developers to have free and easy access to these machine learning tools, and the tool providers like to talk about “democratising” AI. For enterprises, however, the pool of talents capable of deploying such tools for specific business needs remains relatively small, and not all companies have the capabilities or the datasets needed to code and train algorithmic models of their own. Applied machine learning-as-a-service, is therefore emerging as a huge market opportunity for the “enablers”, those who can provide pre-trained models, ready-made application programming interfaces (APIs) as well as customised solutions. Already the major cloud platforms have expanded their offering to include a growing range of machine learning tools and APIs for predictive analytics and cognitive computing services, from machine vision to voice recognition, from classifiers to recommenders.
A retailer without the necessary AI expertise to build and train its own machine learning models can subscribe to Microsoft’s Cortana Intelligence Suite through the Azure Cloud Platform and integrate Microsoft’s AI recommendation API into its own online store, add multilingual chatbot APIs for customer service, and embed image recognition and search capabilities on its website, all without writing its own code or buying its own GPUs. A marketing company running on Amazon Web Services can easily add machine learning to its service package and call on Amazon’s AI expertise to target ads, personalise content, and use natural language understanding algorithms to conduct customer sentiment analysis from diverse sources. An IBM customer from the financial services sector can access Watson Analytics, IBM’s cognitive computing platform, for deep learning-powered systems to conduct risk assessment and guide product development. A logistics operator using Google Cloud can take advantage of Google’s deep neural networks to predict customer demand, optimise delivery routes and schedules, anticipate fleet maintenance needs, and improve energy efficiency at its warehouses (as DeepMind has done for Google’s own data centres – reducing energy consumption for cooling by 40%[7]).
IBM, Google, Microsoft and Amazon, are presently the leaders in this nascent market. Their strengths are not only in their super-sized server farms, armies of engineers and years of deep research, but are also in their being in a position to access large unique datasets as well as their sizeable existing enterprise client base. However, these incumbents have not deterred the start-ups from striving to make a mark with their own machine learning algorithms, architectures and models. H2O.ai and Skymind, for instance, are two upstart “enablers”, each having developed a general purpose deep learning framework, known respectively as H2O and Deeplearning4j, which cater for a broad spectrum of AI techniques and capabilities, ranging from predictive analytics to cognitive applications. The companies have open sourced their frameworks, but earn revenues by charging a fee for customised extensions and enterprise support services. One differentiating feature of Deeplearning4j and H2O is that, unlike the majority of open source machine learning toolkits which are commonly written in Python or C++, they are written in Java, a programming language widely used in enterprise software. H2O.ai, which is a relative early mover and launched in 2011, claims to have more than 5000 entities actively using its technology today. Its customers include PayPal, which uses its software to detect fraudulent listings and has seen a US$1 million reduction in cost per month as a result.[8]
“AI-as-a-service” such as those abovementioned examples can be accessed on cloud platforms or on premises; they can be purchased as ongoing subscription packages or on a “pay per insight” or “$ per 1,000 transactions” basis. The need from enterprises and government organisations for customised solutions is probably even greater. The enablers offer different service models, but it is all pointing to the enormous potential that exists for businesses from all industries to tap into the predictive power of deep learning and use it to gather intelligence and gain insights from big and often unstructured data. (Unstructured data can be understood as everything other than structured databases, whether it is textual, pictorial, temporal, geospatial or relational. It includes data in any medium, from emails to books, from social media posts to call centre voice recordings, from radar signals to satellite images.)
Palantir, one of the most highly valued private companies in Silicon Valley, does not market itself as an “AI company”, but has been a leader in the emerging domain where predictive analytics meet big data. Palantir uses machine learning and other algorithms to find clues, join the dots and identify trends in data. It works with intelligent agencies to track terrorists (and enemies in combat) and helps law enforcement bodies to investigate crimes (e.g. its work contributed to the conviction of Bernie Madoff); banks use its software to detect fraud and predict foreclosures while hedge funds use its services to identify investment ideas and back-test trading strategies. With the venture capital arm of the Central Intelligence Agency (CIA) being its first external investor, Palantir’s client list includes a long string of military and national security agencies of the US government, but the company is increasing its efforts to expand its corporate client base which currently includes financial institutions as well as major consumer goods makers. Its products also serve not-for-profit organisations such as the International Consortium of Investigative Journalists and the National Centre for Missing and Exploited Children,[9] and Palantir frequently makes a point of the contributions its work makes to humanitarian causes like natural disaster relief, helping civilians in warzones, and fighting human trafficking.
A Digression – Why deep learning is only burgeoning
It should be clarified that within machine learning and deep learning (the two terms are often used interchangeably in non-technical settings, including in this paper) there are many different subsets of algorithms and data architectures. They have different features, strengths and quirks, and are therefore suited to different tasks. Convolutionary neural networks, for instance, were first shown to be especially adept in image recognition, while recurrent neural networks are popular in natural language processing systems.
Research papers are being published every week, exploring new machine learning techniques while refining and enhancing existing ones. Some developed what’s known as generative models to perform creative, rather than predictive tasks, such as producing original images, music or text. Others then took a generative neural network and placed it within what is known as an adversarial model with a second neural network, such that the second network can be trained to distinguish between, say, the images generated by the first network from the images of real objects fed to the model externally, thus training the first network to generate better images. Other researchers then came up with the idea to combine generative networks with reinforcement learning techniques to build “intrinsic motivation” into algorithms, to drive “active learning” in machines, meaning that the algorithms are designed to make machines more effective in exploring environments of uncertainty using self-generated rewards.
 Source: OpenAI
Source: OpenAI
A start-up named Geometric Intelligence has developed proprietary algorithms that learn visual recognition at a much faster rate and uses significantly less data than previously publicised deep learning techniques. Google is progressively replacing its already-impressive machine learning-based Google Translate engine with an even more powerful neural machine translation system. Unlike the old algorithms which are “phase-based” and generally break up each input sentence into words and phrases before translating them independently, the new system uses a type of recurrent neural network known as “long short-term memory (LSTM)” which enables it to consider each entire input sentence as a single unit, resulting in more precise and more elegant translations of sentences.
In short, while to the non-technically-minded layperson it may seem like “deep learning is it”, to those well versed in code, there is so much potential for varied and nuanced experimentation and we are only at the early stages of a new Cambrian phase of innovation. This has led to the formation of hundreds of start-ups that offer machine learning products and services. Some, such as CognitiveScale, Sentient Technologies and Ayasdi, to name just a few, have been steadily growing their corporate customer base with their proprietary systems, while others may struggle to compete, as did Ersatz Labs which shut down its cloud-based deep learning platform after two years of operation and now focuses solely on providing consulting and support services. Those with truly innovative technology will have a good chance of going public in several years’ time or getting bought out by the large incumbents, as did Nervana, Turin (acquired by Apple in August 2016) and MetaMind (acquired by Salesforce in April 2016), while those that cannot differentiate their products will find it difficult to compete and will likely disappear with the receding of each tide.
Specialists in Cognitive Computing Applications
In addition to the companies mentioned above, most of which are offering general purpose machine learning tools and services, we are also seeing a growing number of start-ups seeking to differentiate themselves by specialising in select areas of AI application.
In machine vision, for instance, Israeli company Cortica is an early innovator in image recognition and comprehension algorithms and provides visual search and contextual advertising tools, while Affectiva, a start-up spun off from the MIT, specialises in technology that detects human emotions from their facial expressions and other non-verbal cues. BrainCorp, a company funded by Qualcomm Venture, is all about applying machine vision and navigation systems to enable autonomous devices (like its robot cleaners) to function in complex physical environments. Intel’s Internet of Things Group recently acquired a similarly-focused start-up, Itseez, which has a suite of computer vision algorithms and implementations in hardware ranging from cars to surveillance videos, to robotics and smartphones.
In voice recognition, KnuVerse, an affiliate of the aforementioned specialist chip-maker KnuPath, has launched a human voice biometrics technology that enables instantaneous identity verification and authentication with words spoken in any language and even in “noisy, real-world conditions”. Initially available only to the military, the technology is now being marketed to enterprises with promises to dramatically improve voice-machine interfaces.
In the domain of natural language processing and natural language generation, start-ups such as Automated Insights, Narrative Science and Yseop are providing specialised software to enterprises to perform a range of analytical, reporting and descriptive functions. Their algorithms are used by media companies like Reuters and Forbes to generate news reports, which are increasingly articulate, sometimes indistinguishable from those written by humans. Their algorithms also complement conventional business intelligence software that focuses on presenting patterns in big data through graphics (e.g. products by Tableau and Qlik) by describing and explaining those patterns in plain language narratives.
Bots, Bot-Builders, and Conversation-as-a-Platform
Advances in natural language processing are also leading a new shift towards what Microsoft’s CEO Satya Nadella called “conversation as a platform” and chatbots have become an area of much hype. After opening the Messenger Platform to developers in April 2016, Facebook accumulated more than 33,000 bots within just five months.[10] From cab hailing to flight booking, from flower delivery to tracking sports scores, businesses are busy building bots to integrate their services with popular messaging platforms like Facebook Messenger and WeChat (and as stand-alone services) via speech as an interface. Plenty of start-ups have sprung up to service those needs by providing the tools for building and training chatbots and deploying them on a range of hardware (mobile, wearables, and automated home devices) and mediums (messaging apps, websites, emails, SMS). Motion.ai, for instance, prizes its modular bot-building system for its ease of use, which it claims to allow others to build a bot “without touching a line of code”. Sequel (owned by start-up Kiwi Inc), on the other hand, claims to allow users to create personalised bots, bots that take on individual personas. Sequel’s “PublisherBot” product targets publishers, brands and entertainment companies, while its “PersonalBot” is described as an ideal tool for celebrities, social media influencers, advocates, and anyone else wishing to attract fans and engage with an audience as it generates content while mimicking their personality.
As start-ups catch on the trend of conversational user interface (CUI), big techs are busy scooping up promising start-ups to complement their internal R&D, but more importantly, to boost their developer base in a new era of dominance by personal messaging apps. In January 2015 Facebook acquired the 18 month old Wit.ai which at the time had around 6,000 developers using its speech-to-text bot-building toolkit. The toolkit remained open and free, and is used by more than 45,000 developers today.[11] Wit.ai’s easy-to-use technology presumably contributed no small part to the popularity of the Messenger Platform, which Facebook hopes will turn Messenger into “a canonical, contextual place where you can have all of the interactions you can have or need to have with a brand or service”.[12]
Facebook’s “master plan” for a “master app” is not new – Chinese company Tencent pioneered the idea through its WeChat app, but Facebook’s plan is an ambitious one, as it threatens to weaken the relevance of operating systems like Google’s Android and Apple’s iOS and to divert a good deal of traffic from Google Search, the gate-keeper to millions of websites and the backbone of Google’s ad revenue.
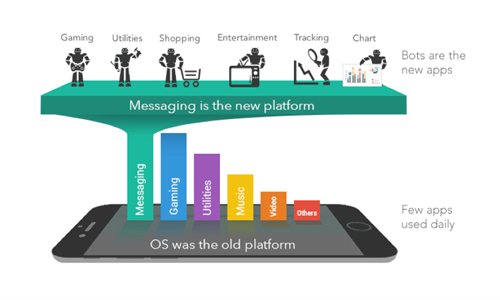
Source: Beerud Sheth https://techcrunch.com/2015/09/29/forget-apps-now-the-bots-take-over/
Apple has responded by recently opening up its AI assistant, Siri, to third party developers, so that it can be incorporated into other apps that run on the iOS, as well as upgrading iMessage from a rather basic messaging app into a platform that hosts other apps. Google, of course, has many grand plans as it evolves from a “search first” company into an “AI first” company, and CUI plays a big part. Just days after Apple released iOS10, Google launched a new messaging app named Allo, which similarly hosts and integrates other apps. Allo also comes with the Google Assistant, a new voice-enabled, machine learning-powered bot that is a formidable rival for Siri. Around the same time that Google launched Allo in September, it also announced its acquisition of Api.ai, another start-up specialising in bot-building algorithms. What makes Api.ai attractive is that it currently caters for 15 languages and dialects, has more than 60,000 developers using its toolkits, has processed over three billion API requests to date,[13] and its virtual assistant app, Assist, had amassed more than 20 million users.[14]
Where Google trails Facebook in terms of lacking the latter’s vast social network base, Google is hoping to make up (and outdo) by leveraging its deep expertise in search and machine learning to make the Google Assistant super intelligent. In fact, Allo was only an overture, the real star is Pixel, Google’s new smartphone offering with the Assistant integrated throughout the operating system, both delivering and garnering intelligence through collecting new data with the user’s every move (similar to Siri’s role in iOS10). The Assistant also powers Google Home, the voice-activated speaker that answers questions and controls other connected smart devices throughout the home. The device is similar to Amazon’s Echo, which is powered by Amazon’s AI system named Alexa, but has Google’s “brain”, so to speak. The Internet of Things (IoT) certainly does not end with home appliances or smartphones – one can almost be certain to also find the Google Assistant in Google’s autonomous cars, when they are finally released.
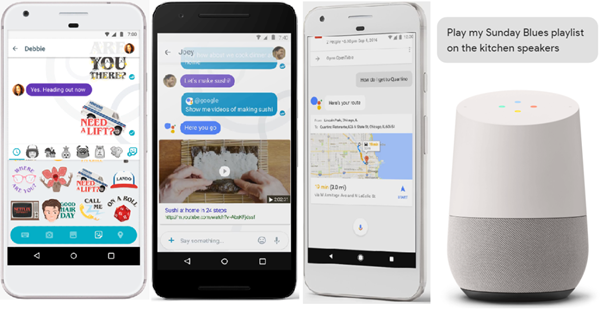
Google’s new messaging app, Allo; Google Assistant in its Pixel phone and Google Home. Source: Google.
Some have observed that the Google Assistant is available only in Pixel phones (i.e. as integrated throughout the operating system, not just in the Allo messaging app), and other Android phones are missing out. This is probably not great news for the current makers of Android phones, and in part explains the significance of Samsung’s recent acquisition of Viv, the start-up founded by the original creators of Siri who had subsequently left Apple to develop a new AI-based voice-controlled digital assistant. Voice as a platform, powered by deep learning, is simply too important a trend to miss.
AI-Appliers across Industry Verticals
As machine learning techniques become increasingly sophisticated, their applications are beginning to have a meaningful impact on industries, augmenting some, while disrupting others.
In financial services, for example, AI is being deployed on various fronts. Lenders use machine learning technology for credit assessment and default prediction; insurance companies use it to analyse risk and price insurance policies; compliance professionals use AI to detect money laundering, insider trading and other fraudulent practices… The most promising is probably AI’s foray into wealth management. Robo-advice and algorithmic trading have attracted much attention in the last decade. Some early iterations of these systems generally follow hard-coded, quant-based rules, and not all models can be called sophisticated. Their edge comes not from insight or foresight, but largely from cost savings as a result of automated processes and, in the case of algorithmic trading, an advantage in execution speed and timing. But deep learning is different. Its ability to detect patterns in big data and make increasingly accurate predictions based on them has the potential for making truly discerning investment decisions. Powerful deep learning algorithms take statistical models beyond economic data and financial metrics to incorporate a wider range of information that can impact on market movements in the long- or short-term. One can imagine systems that distil meaningful patterns from unstructured data, unconstrained by source or medium, from scouring voluminous reports using natural language processing to studying complex images, whether they are meteorological pictures for predicting agricultural production or geological findings relating to oil exploration. Principles of behavioural finance can be “learnt” from historical data and investor biases recognised in real-time market movements. It is no surprise that asset managers with a penchant for modelling are upgrading their tools and snapping up AI talents, while some machine learning experts are seeking to apply their trade to good use by starting their own investment funds. It remains to be seen whether the new generation of AI-driven asset managers, such as Rebellion Research, Numerai, Aidyia and Sentient Investment Management, will bring about a true paradigm-shift in investing.
A deeper example of an industry undergoing profound transformation as a result of big data and machine intelligence is healthcare. As noted in a recent presentation by Dr. Bianca Ogden, Portfolio Manager of the Platinum International Health Care Fund, “Data, its analysis and interpretation will change the dynamics in healthcare over the next decade.”
Bianca explained in her presentation how big leaps in DNA sequencing technology are making vast amounts of genetic data available to scientists and clinicians which have driven the development of precision medicine, a personalised approach to the treatment of diseases that “takes into account individual variability in genes, environment, and lifestyle”.[15] However, the new challenge lies in making sense from the data, understanding the differences between an individual patient’s genetic data and the reference datasets, and determining which differences have significance and what treatments are needed in the context of published literature, clinical trials and other knowledge bases. Similarly, the development of drugs and therapies that better target diseases at a molecular level, such as more sophisticated antibodies, RNA interference (RNAi) and immunotherapy, also relies heavily on data crunching tools that can investigate signalling pathways and identify cell mutations.
Refer to Bianca’s presentation for a discussion on some of the leading biotech companies with a strong focus on data-driven research (such as Qiagen, Roche and AstraZeneca). In addition, the importance of the algorithms used to analyse and interpret data has also created a new stage for those tech companies that can put AI capabilities to a range of medical use, from diagnostics to drug development, from precision medicine to combination therapy.
Capitalising on its years of research into AI that culminated in Watson, the supercomputer that in 2011 defeated two world champions at the quiz show Jeopardy!, IBM is one of the first movers in commercialising AI and cognitive computing. Watson is being employed to service a range of industries, but healthcare is where IBM has been particularly active, having bought a number of start-ups over the past two years, which allow it to access some 300 million patient records for data and insight. One of Watson’s earliest deployments is IBM’s collaboration with the Memorial Sloan Kettering Cancer Centre (MSKCC) in 2012 to build a system for cancer diagnosis and treatment. Watson first “learned” millions of pages of medical text and tens of thousands of patient cases. Using natural language processing and hypothesis generation systems, it analyses patients’ medical information and recommends individualised treatment options, which are ranked and backed up by a detailed record of the data and supporting evidence used to reach the recommendations. The technology is a valuable resource particularly for regions with a shortage of medical experts, and the company is introducing Watson for Oncology across India, China and South-East Asia. Since the MSKCC, Watson has collaborated with many other medical institutions and is also used by big pharma such as Sanofi and Johnson and Johnson in their drug research.
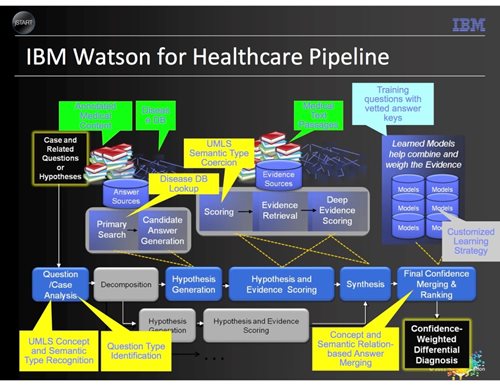
Source: IBM
Unlike IBM, Google has, until recently, only been utilising deep learning to enhance its own products and services (e.g. search, Google Map), rather than to fully commercialise the technology as a standalone business. However, few are sceptical about the depth of Google’s research or the potential for its technology to be useful to industries. Shortly after AlphaGo’s historical win at Go, the DeepMind team began putting its technology to real-world uses and formed a partnership with the UK’s National Health Service (NHS). DeepMind will train its deep learning algorithms to diagnose eye diseases such as age-related macular degeneration and diabetic retinopathy, using around a million anonymised eye scans from the Moorefields Eye Hospital’s patient database. The aim is for machine vision and other AI techniques to help doctors to perform more comprehensive analysis of complex eye scans with greater speed and precision, thereby facilitating earlier detection of the diseases, which can prevent many patients from becoming blind. In another project, the University College London Hospital is giving DeepMind access to hundreds of CT and MRI scans from former patients with head and neck cancers to develop deep learning algorithms that can perform fast and accurate segmentation in radiotherapy planning, which is the process of mapping out in detail the area to be treated and isolating cancerous tissue from healthy tissue (so as to avoid damaging the healthy structures and nerves during radiotherapy) and currently takes doctors hours to perform.
Microsoft recently launched several projects with the aim to “solve cancer”, from helping radiologists to better track tumour progression using CT scans to modelling complex cell activity to find targeted treatments, to a “moonshot effort” to program biological cells as we do computers. One of its research teams created Bio Model Analyzer (BMA), a cloud-based tool for building computerised models that compare the biological processes of healthy cells with the abnormal processes of cells affected by disease. By enabling scientists to examine the interactions between the millions of genes and proteins in the human body, the system not only gives insights into how cancer develops in a patient and therefore helps with early detection, but can also predict how the patient might respond to various medications through simulated models of molecular activity. AstraZeneca is partnering with Microsoft to apply BMA to research drug interactions and resistance in patients with leukaemia.
The same idea applies to broader drug discovery. As there are countless variables in how the millions of molecules, proteins and genes may react and interact, without powerful computer programs biologists can only test a limited number of hypotheses, chosen with the risk of human bias. This is part of the reason for the high failure rates of traditional drug development process, despite costly clinical trials. Machine learning based tools can change that. They can speed up drug discovery, increase success rates and save costs by more accurately predicting the therapeutic effects, adverse effects and toxicity levels of different molecules in pre-clinical “in-silico” testing (i.e. the testing is done in silicon based computers, rather than biological bodies). This may indeed change industry dynamics and allow AI-centric newcomers like Berg Health and Cloud Pharmaceuticals to make a mark.
There is also no shortage of start-ups using AI to make inroads into parts of the healthcare chain other than diagnostics and biotech research. Lumiata and NextHealth Technologies, for example, are providers of predictive health analytics to insurance companies, hospitals and doctors for risk and care management. Their machine learning systems analyse patient data to generate insights and predictions related to symptoms, diagnoses and treatments, and aim to improve patient care while lower the costs for care providers. Ginger.io, on the other hand, is more patient-oriented and uses its predictive models to provide personalised self-care and monitoring systems to patients suffering from mental health issues. In short, AI’s presence is beginning to be felt in all segments of the healthcare vertical.
Everyone will be an AI-Applier
Commentators often say that machine learning will have a significant impact on the “data-heavy”, “information-intensive” industries, and healthcare and finance are often touted as being among the most “ripe for AI disruption”. In fact, these are just the early adopters, and eventually every industry will be an AI-applier, because all industries are ultimately driven by information and just about all forms of information are now translatable into digital data. Humans have not always been good at conceptualising what we do through the lenses of computers – before the dawn of autonomous vehicles, few traditional automakers would have thought about the task of driving in terms of bits and bytes of data. However, as human-inspired machine intelligence becomes ever more human-like, it will in turn inspire us to find more ways to utilise AI.
Autonomous vehicles (AVs) are a good example of how different players may approach the same task differently as they conceptualise the problem differently. This paper by Curtis Cifuentes, one of Platinum’s long-standing tech sector investment analysts, contrasts the approach of traditional automakers – through incremental and piecemeal improvements to partly automated systems – with that of the tech companies, which start with the assumption that cars can be trained to drive entirely on its own and focus instead on sensors, algorithms and data. Also contrast Google, whose deep resources allow it to design and build a new prototype vehicle from the ground up to be fully autonomous, with no steering wheels or pedals, with the approach of the aforementioned Comma.ai, the start-up that is aiming to sell kits that can be retrofitted on most of today’s car models to make them autonomous for less than US$1,000 each. Google has not released to market its self-driving bugs after six years and nearly 2 million miles of testing,[16] yet, Comma.ai is planning to ship its kits by the end of 2016! As for gathering data and training the AI: Google continues to train its AVs in real-world conditions under research mode, while ride-sharing company Uber feels the time has come and now trains a self-driving fleet (accompanied by human “supervisors”) in Pittsburgh, Pennsylvania while giving free rides to passengers. Tesla has the advantage that its cars are already running all over the world and are gathering data at a million miles per week from its some 25,000 drivers[17] – though, mind you, that is driving done by humans, not the cars themselves. Comma.ai also believes in training its algorithms with data from how human drivers behave on the road, but it has no fleet of its own. Instead, the company launched “Chffr (pronounced "chauffeur")”, a smartphone app that tracks users’ driving habits and feeds the data back to the company to train its algorithms. With so many manufacturers and developers racing to get their AVs on the road, AI is giving the auto industry a true overhaul.
***
Like in the mid-1990s when the Internet was on the verge of taking off, and towards the end of the last decade when smartphones “tipped”, the acceleration of deep learning research over the past few years has arguably brought us to yet another historic juncture. The foundations of machine intelligence have been laid, and as its commercialisation gathers pace, new terrains are opening up for businesses. From the “AI enablers” to the “AI appliers”, from the owners of existing major platforms to those who can aggregate unique datasets in a niche market, the opportunities are indeed wide and varied.
However, as investors, beware of those exponential charts that one all too often sees as being associated with AI, whether it is an unwavering curve that purportedly depicts humankind’s seemingly inexorable move towards the so-called Singularity, or one that attempts to forecast the so-called “total available market” or TAM. There is no doubt that the opportunity set will be enormous, but it does not simplistically translate into any specific company’s profit or share price trajectory. Some of the companies with a strong focus on deep learning, like Google, Intel and Baidu, are long-time holdings in Platinum’s portfolios, but we also expect to see an evolving AI ecosystem.
[In Part 3 of this series we will discuss some of the ethical issues (like privacy and transparency) as well as the socio-economic challenges stemming from the rise of AI.]
DISCLAIMER: The above information is commentary only (i.e. our general thoughts). It is not intended to be, nor should it be construed as, investment advice. To the extent permitted by law, no liability is accepted for any loss or damage as a result of any reliance on this information. Before making any investment decision you need to consider (with your financial adviser) your particular investment needs, objectives and circumstances. The above material may not be reproduced, in whole or in part, without the prior written consent of Platinum Investment Management Limited.
From the journal

Lessons with an investment professional - nine more tips
Douglas Isles' tips explore the hidden dangers of a headline and the power of quality.

Investment lessons with a pro - the front nine
Doug Isles draws on 18 years' experience to talk cliches, hype and the perils of past performance

Scottie Scheffler and the ‘happy amateur’ investor
What can investors learn from the distinction between amateur and professional sport?

It’s a living thing – investing in biologics
Adrian Cotiga explains the rationale behind Platinum's investment in biologics company Lonza.
Subscribe to Platinum
Receive our expert investment insights and market updates.
Journal Articles
Read market leading insights.
Market Updates
Get market updates from our analysts
Quarterly Reports
Receive quarterly investment reports