
Having considered some of the exciting potentials of AI, let’s now examine some of the challenging issues presented by the prospect of self-improving systems with increasingly human-like and super-human aptitudes, be they the threat of mass unemployment, the erosion of privacy, or simply the inability to understand and trust the technology.
Part 3 of 3 – The Ultimate Test of Human Intelligence
As seen in Part 1 and Part 2 of this series, it is hard not to feel excited about machine learning. First, it empowers machines to teach themselves the tasks that humans can perform but find difficult to “teach” a computer via conventional coding (e.g. vision and understanding natural languages). Secondly, it enables computers to perform tasks that far exceed human abilities, like analysing terabytes of data at lightning speed to unearth hidden patterns and make sense of them. But it is also hard not to feel some unease about the prospect of self-improving computer systems with increasingly human-like and super-human aptitudes, whether it is the threat of mass unemployment, the erosion of privacy, or simply the inability to understand, validate and trust the technologies that will increasingly impact our lives. These problems that artificial intelligence (AI) is throwing back at us are complex and multifaceted, and to tackle them requires concerted endeavours by our technologists, entrepreneurs, lawmakers and thinkers from all fields and walks of life. It will be a test of humankind’s collective wisdom to ensure that our social institutions keep up with our technological progress.
The Economic, Legal and Ethical Challenges of Autonomous Vehicles
The advent of autonomous vehicles (AVs) illustrates the wide-ranging economic, legal and ethical questions that new technologies raise. AVs are already roaming the streets and conveying passengers in parts of the world, and many more are expected to hit the roads over the next five years as tech companies like Google, Baidu and Lyft race against incumbent automakers to make reliable and affordable self-driving cars. This is likely to dramatically alter the economics of transportation, from ownership rate to utilisation rate. It is estimated that in the US and the UK our cars on average are being driven just 5% of the time and they spend the remaining 95% in a garage or a car park.[1] That ratio may well be reversed if the availability of door-to-door transport is no longer linked to the availability of human drivers. In conjunction with ride-sharing apps and other tools that can communicate and coordinate supply and demand in real time, a smaller fleet of AVs may be able to serve the needs of a population with most individuals and families no longer needing to own cars of their own.
Not only will this directly impact on auto sales, there will also be flow-on implications for insurance, urban planning, infrastructure capacity and much more. If self-driving cars are indeed safer than human drivers and will substantially reduce the number and severity of traffic accidents, vehicle insurance premiums may fall significantly over time. Indeed, if widespread AV adoption triggers a shift of legal liability from driver-owners to manufacturers (see discussion below), there may need to be a new insurance model altogether. If families no longer own cars, dreary garages can be converted into additional living space. If most cars are shared and spend most of their time on the road, concrete car parks can be turned into public green space or have the valuable real estate freed up for other use. Will people use more or less public transport when on-demand AV services are readily available? Will traffic congestion improve or worsen as a result? Will suburban housing become more attractive as commuting becomes less straining and commute time more productive?
Regulatory frameworks need major “upgrades”
A more pressing issue is the need to “upgrade” our regulatory frameworks that govern safety standards, vehicle registration, insurance and licensing, as well as to reconsider the legal principles that determine duties of care and liability. Urged by their fast-moving tech companies, regulators in the US have been paying considerable attention to this area. While traffic laws and motor vehicle regulations have traditionally been the domains of state governments, the Department of Transportation (DoT) at federal level issued a detailed set of policy guidelines in September with the aim of establishing a foundation for AV regulation. The policy provides 15 points of guidance with respect to the design, development and testing of AVs prior to commercial sale or operation on public roads and requires manufacturers to assess and report on their products accordingly. The areas covered range from system safety and vehicle cybersecurity to data sharing, consumer education and ethical considerations. It will be interesting to see how industry players respond to and ultimately implement these guidelines.
The policy also contains a Model State Policy which, though not binding on state governments, aims to promote “a consistent, unified national framework” for AV regulation. So far state laws regarding AVs have been a hodgepodge. Starting with Nevada in 2011, a handful of states have enacted legislation that expressly permits the operation of AVs on public roads under certain conditions and deals with related safety and liability issues in various ways. Some, such as Florida and Michigan, no longer require a human driver to be present in the vehicle, while others (e.g. Washington DC) still mandate that a human driver must be “prepared to take control of the autonomous vehicle at any moment”. Proposals to allow the testing of AVs on public roads have been rejected by several state legislatures while in certain other states in the US (and in many other countries) it remains an open question – there is simply no law either authorising or prohibiting the operation of AVs on public roads. One hopes to see more governments around the world play a more active role in facilitating the development and adoption of a technology that promises to reduce road deaths and improve efficiency.

Source: Automotive IT News
Are existing liability regimes adequate?
Even in those US states where laws relating to AVs have been passed, the question of liability in the event of an accident remains entirely unclear. Under existing traffic laws, the at-fault driver whose negligence caused the accident is generally liable. But how does this principle apply in the absence of a human driver? Michigan legislation provides that “when engaged, an automated driving system […] shall be considered the driver or operator of the vehicle for purposes of determining conformance to any applicable traffic or motor vehicle laws”.[2] This highlights the problem, but does not answer the crucial question of who the deemed driver is, or, in other words, who or what the legal person to which legal liability can be attributed is. Some lawmakers appear to be thinking along the lines of shifting liability from the driver to the manufacturer and deferring to existing product liability laws. For example, Florida law expressly limits the liability of the original manufacturer of a vehicle converted by a third party into an AV against claims of vehicle defect caused by the conversion,[3] but leaves open the question of the liability of the designer and/or manufacturer of the autonomous technology or the converter that installed such equipment onto the vehicle. A similar provision exists under Michigan law, but there a manufacturer’s liability (and its obligation to insure the vehicles) appears to be bound up with the manufacturer’s role as a provider of on-demand AV services[4] (think Uber and the AV fleet that it owns and operates), so it is unclear what the position is if the manufacturer and the on-demand AV service provider are unrelated entities. For now legislators seem inclined to leave the difficult questions to the courts. Meanwhile, some manufacturers (e.g. Audi and Volvo) have announced of their own accord that they will assume legal responsibility for any crashes or fatalities from their self-driving cars.[5]
Even if individual victims of accidents may have recourse against manufacturers, relying on the product liability regime to fill the new void in traffic accident liability may not necessarily be an optimal policy choice. It could potentially drive up costs for the industry (and ultimately the consumer) and slow down innovation and adoption. An ideal outcome will be a significant reduction in traffic accidents, as AV developers are predicting, and hence a diminishing number of related claims. If, however, litigation does become a costly burden on the industry, further policy response will be necessary, and possible response may include, for example, enacting legislation to limit liability, as is the case in the commercial airline industry, or creating a common insurance fund to spread the risk.
The legal and ethical challenges presented by self-driving cars foreshadow the more complex questions to come as we develop more and more capable AI systems and as these systems perform more and more important functions in our society, from risk assessment to portfolio management, from diagnostics to aged care. Without venturing into the realm of AI personhood and legal capacity potentially independent from human agents – which may eventually become a real question in the far distant future, perhaps when artificial general intelligence (AGI) becomes a reality – we nevertheless need more conceptual tools to consider the role of self-modifying AI systems than treating them as inert products. To what extent can and should the different human agents (e.g. designer/creator, owner, and operator/user) be held responsible for the decisions or recommendations of a machine learning system that continues to learn and evolve after being deployed? What if the poor decisions made by an AI system are the unintended result of collective biases embedded in the datasets used to train the system (see further discussion below)? Even within existing liability regimes, one can see that legal concepts such as forethought, negligence and foreseeability will likely need to be redefined.
Will commercial realities resolve ethical dilemmas?
One context in which AV manufacturers, or more specifically, the parties responsible for an AV’s algorithms, face more than just potential law suits is the vexing ethical question known as the Trolley Problem. Imagine a hypothetical situation where a self-driving car is faced with a choice between two adverse outcomes, say, between killing three elderly pedestrians by going straight ahead and killing a young cyclist by swerving the vehicle to avoid hitting the pedestrians. For a human driver, it would be a split-second decision driven by instinct without forethought. But for a self-driving car, the course of action may be predetermined or at least significantly influenced by its algorithms which would have been consciously designed by its coders. So how should an AV be programmed to react in such a situation? What if the pedestrians were crossing illegally or if the cyclist was on the wrong side of the road? What if it is a choice between a pedestrian and a passenger in the car? Should the law mandate the hard-coding of a certain utilitarian decision tree into all AVs, or should the operator or passenger be allowed to adjust each vehicle’s “ethical setting”?
The US DoT’s policy guidance acknowledges the dilemma, but does not prescribe any particular decision rules other than that “the resolution to these conflicts should be broadly acceptable” and that the algorithms “should be developed transparently using input from [regulators], drivers, passengers and vulnerable road users”. What “broadly acceptable” means, however, is not so easy to determine. Research surveys show a range of different views, unsurprisingly. One study found that while most participants support the idea of AVs being pre-programmed for utilitarianism (i.e. minimising the number of casualties), when it comes to purchasing an AV, they were split between those that would sacrifice the passengers, those that would not, and those that would randomly pick a course of action.[6] Another survey found 64% of the participants would rather have the car kill a child running across the road illegally than sacrificing the passenger.[7] So, in the absence of any mandatory standard, would customers buy “self-sacrificing” vehicles if there were less altruistic models that “always put the passenger first”? Mercedes-Benz recently declared that its future AV models will always prioritise saving the passengers.[8] It seems that commercial reality may in the end dictate the direction to be taken to resolve the once hypothetical ethical dilemma.

Credit: Kiana Johnson | Source: Daily Texan
Towards More Transparent, Accountable and Equitable Algorithms
As machines become increasingly skilled at mimicking aspects of human cognition, they have ironically also inherited human biases and learned to discriminate. The algorithms used by some US law enforcement agencies to predict recidivism have been shown to be both inaccurate and biased against black people (statistically both overestimating the chance of re-offending by African Americans and underestimating that by white offenders).[9] Google’s ad-targeting algorithms display more high-paying executive job ads for male users than for females.[10] Fake news with sensationalist headlines began to trend on Facebook’s news feeds when click-through rates replaced editorial judgement as the arbiter of newsworthiness, while personalisation filters misrepresent confirmation bias as “relevance”, blocking opposite viewpoints and entrenching preconceptions. These controversies have raised awareness about the risks and harms of algorithmic biases and led to calls for greater accountability on automated decision-making.
How do algorithms develop biases?
In a traditional rule-based system, biases can be hard-coded into the system, such as when Google Search used to favour its affiliates (e.g. Google Health) when ranking search results,[11] or if a screening program applies filters based explicitly on protected attributes like race or gender. This type of overt bias is both relatively easy to detect on a technical level and more likely to be held accountable under anti-trust laws or anti-discrimination laws. Detection and correction are more difficult with statistics-based systems like machine learning where the source of bias is usually embedded and distributed in the dataset used to train the model. Consider a supervised learning algorithm designed to spot offensive images online and is trained using millions of images that are classified by humans as either “offensive” or “inoffensive”. If the crowdsourced labellers on the whole (not any particular individual) have a conservative tendency and have flagged a large proportion of images with nudity as offensive, regardless of their artistic merit or intent, the algorithm will likely take on that conservative bent. Even if the initial training datasets are checked for biases and the model is given a balanced and “healthy” learning environment, there is the risk of “corruption” after deployment into the real world. A case in point is the chatbot, Tay, which Microsoft was forced to withdraw within less than 24 hours of launch because Twitter denizens had turned its polite and friendly persona into a racist and misogynist by inundating it with abusive tweets. Like children who learn by observing those around them, machine learning algorithms learn continuously by example and will pick up on “surrounding” influences from the data they absorb.
Biases can also arise when the training data is not sufficiently representative of the real world user case. A machine learning model may fail to correctly recognise and classify a category of objects, people or situations if it has not been exposed to sufficient examples of them. This selection bias in the training data is what caused Google’s image recognition app to mistakenly label a black couple as gorillas and explains why Microsoft’s speech recognition API failed to recognise female voices. These so-called “blind spots” in algorithms can have serious repercussions in real life if they occur in mission-critical systems such as self-driving cars and medical diagnostic tools.
Another concern is that machine learning systems can unintentionally exacerbate and perpetuate human prejudices and structural biases by virtue of their precedent-driven approach to improve accuracy in predictions. We see this happen when auto-complete, ad-targeting and other algorithms using word-embedding techniques reinforce gender and racial stereotypes because of their prevalence in human-generated examples (e.g. associating men with “computer programmer” and women with “homemaker”; juxtaposing “black male” with “assaulted” and “white male” with “entitled to”).[12] We see this happen with crime prevention algorithms assign high risk scores to a particular racial group on the basis of factors such as past criminal record, education, employment status and association with others with criminal history. This is not necessarily the result of discriminatory intent on the part of those who designed the model or statistically skewed historical data – that the group has a high crime rate historically is a fact. However, regardless of whether the profiling actually generates accurate predictions or in fact reduces crime, it can result in that particular racial group being targeted more often by law enforcement officers, lower chances of being granted bail and parole, and tougher average sentences, thereby perpetuating the socio-economic problems of an already marginalised community. This is not bias in the statistical or technical sense, but bias in a sociological and ethical sense.
Worse still, even if protected attributes such as race and ethnicity are withheld from the algorithm (i.e. the data fed to the model does not contain explicit information on these attributes), they may still be inferred implicitly by the system from legitimate parameters (such as employment status, education level and address) and play a role in the computational process as hidden variables, resulting in predictions being generated that has the inadvertent effect of being discriminatory and unjust.
What can be done to fix machine biases?
Concerned with the potentially detrimental impact of discrimination by algorithmic decision-making, EU lawmakers recently enacted a controversial General Data Protection Regulation which grants individuals a “right not to be subject to a decision based solely on automated processing, including profiling”, if they are significantly affected by the decision. The trouble is that such a provision may be applied to prohibit a broad range of programs from being used,[13] potentially covering not only algorithms that lenders rely on for credit assessment and screening systems used by recruiters and employers, but also product recommenders in online stores and news feeds on our smartphones.
Curbing the use of technology-based services and tools is neither the objective nor an effective solution. The challenge is to ensure that automated systems are used responsibly to make non-discriminatory and fair decisions. It is clearly a complex problem and requires a multi-disciplined approach to develop the necessary technical, regulatory and cultural tools to solve it. As many industry experts have noted, it starts with improving diversity and inclusion among engineers and product developers so that the systems they create will reflect a more rounded understanding of the world, one that integrates different racial, gender, cultural and socio-economic perspectives, is context-savvy and minimises “blind spots”. Appropriate training in psychology and the social sciences may also help the engineers to identify and overcome their own unconscious biases in their design choices, control and mitigate other sources of bias in the collection, selection and presentation of training datasets, and be mindful of the social and ethical implications of the system’s deployment.
There is also an active research community exploring various technical methods to audit training data for bias, test models for discriminatory results and fix algorithms to improve neutrality and fairness.[14] Some have considered the pros and cons of applying the disparate impact theory to measure the fairness of predictor algorithms. It broadly entails calibrating the model to achieve statistical parity across different demographic groups by protected attributes, but may compromise fairness in the sense of reduced accuracy within certain groups.[15] Others are proposing an approach to eliminate discrimination from a supervised learning system by optimising the predictor to deliver “equalised odds and equal opportunity” while keeping the model oblivious to the protected features.[16] None of these techniques are perfect, but with the right objective and the right design, intelligent machines have the potential to help humans avoid the pitfalls of our cognitive biases and heuristics, rather than to reinforce and exploit them.
Can we open the black box, or otherwise live alongside it?
The checking and monitoring of algorithms involved in important decision-making should not be the sole responsibility of those that designed and created them, user awareness is also important. It helps with more informed and considered decision-making if the individuals and institutions employing algorithms for analytics and intelligence appreciate the probabilistic nature of their predictions and recommendations. Moreover, because perfectly balanced and representative datasets are rare, if not impossible, no data-driven model is wholly objective and value-neutral, and machine learning systems will inevitably reflect a degree of human subjectivity and bias.
Many argues that to assess the efficacy, fairness and accountability of an automated decision-making system, and to determine how much it can be trusted, one needs to know how the algorithm works and end-users and other stakeholders should have a “right to explanation”. However, this raises the difficult black box problem. Unlike rule-based systems, the inner workings of machine learning algorithms are often too complex to explain. Deep neural networks are especially impenetrable. With their intricate multi-layers of mathematical abstractions and continuous self-adjustment of the parameters and weights embedded in the model, even the engineers that created the model may not have full clarity into – let alone explain in plain English – how a deep learning algorithm takes a particular input and ends up with a particular output. This is in a way unsurprising if we think about how little we know about how our brain functions and how fraught with difficulty it is to articulate the neurological processes of human cognition.
Credit: Brennen Bearnes | Adafruit
The following example demonstrates both the dangers of data bias and the benefits of intelligible algorithms. A neural net model was used in one study to predict which pneumonia patients would develop complications. Having correctly identified a correlation in the training data between patients with asthma with patients who did not require further care, the model incorrectly classified patients with asthma – long considered a high-risk category by doctors – as being low-risk. The reason that those asthma sufferers in the training data had not developed complications was due to a hospital policy that automatically sent all patients with asthma to intensive care. However, unaware of this bias in the underlying data, the system mistakenly concluded that having asthma makes a pneumonia patient less likely to develop complications when in fact it is the opposite case. This erroneous inference by the neural net model was detected by another type of algorithm which, by virtue of it being intelligible and modular, is also able to remove those anomalies and improve the system’s reliability.[17]
Despite the technical challenges, some researchers are working to find ways to peer into the black box. Some are using reverse-engineering to deconstruct algorithms and reconstruct how they represent various features.[18] Others are attempting to extract rules from neural networks, “to translate this numerically stored knowledge into a symbolic form that can be readily comprehended”.[19] These techniques do not work effectively on all machine learning algorithms and the problem gets more difficult as the neural nets get deeper and more elaborate. Moreover, they also risk exposing the system to potential breach and abuse, leading some to argue that algorithmic transparency is not necessary a good thing. Some argue that transparency, in the sense of visibility into the source code, is often neither necessary (because of alternative techniques) nor sufficient (because of code complexity) to verify whether an automated decision-making system is fair and non-discriminatory, and they prefer to instead explore other design and audit techniques to improve algorithm accountability.[20] One of the challenges, for example, is to create machine learning systems that are aware of their own uncertainty and can explain to humans the bases for their predictions. By most accounts, teaching statistics-based algorithms to distinguish between causation and correlation – something that humans often find difficult – is still a major struggle.
Notwithstanding these research efforts to tackle the black box problem, there are limits (at least for now) in how far some machine learning algorithms can be deconstructed and verbalised in a reductionist humanly-comprehensible form. Yet, the impact these systems have on the real world is becoming increasingly far-reaching and profound. It is therefore necessary to develop ways to evaluate algorithms without knowing the exact ins-and-outs of their inner workings. The great tech writer and publisher Tim O’Reilly offers a four-point guide to assess whether a black box can be trusted without being able to see through it. Firstly, what the algorithm is aimed to achieve must be made clear and that goal needs to be verifiable. Secondly, how successful the algorithm is at achieving its goal needs to be measurable. Thirdly and importantly, the goals of the algorithm's creators should be aligned with that of its users. The last criterion is also an important one: the algorithm should lead its creators and users to make better longer term decisions.[21] One can see that many of the above examples of machine learning models with data biases or generating discriminatory outcomes will be caught out. Although these tests may not be easy to apply in practice and the latter two questions in particular may not yield clear-cut answers, this is nevertheless a very useful framework for evaluating automated decision-making systems and formulating appropriate regulations for their deployment.
Striking a Balance between Privacy Protection and Data Utility
Data’s importance to machine learning systems is now a well-known fact. Many of the concepts and techniques that led to the latest AI breakthroughs were in fact first proposed decades ago, but the breakthroughs did not come through until recently because there was a lack of high-quality training data. In machine learning, the size and quality of the datasets can make an enormous difference to the accuracy of the model (the chart below illustrates the average performance improvement in two types of algorithms). Recent AI achievements have been made possible by the growth of big data over the past three decades which witnessed internet access and mobile connectivity rapidly spreading worldwide, a proliferation of digital equipment like cameras and sensors, and the digitisation of services ranging from e-mail to e-commerce. Today, 2.5 exabytes (= 2.5 billion gigabytes) of data are generated across the globe every day.[22]
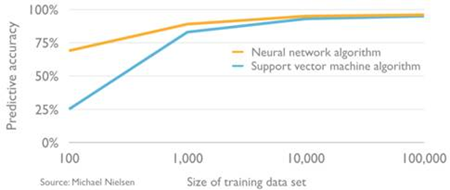
Source: Michael Nielsen, David Kelnar
As we generate more and more digital data in our daily life, we are also becoming more and more concerned with who have access to that data and what they do with it. It is indeed disturbing to find image recognition algorithms rendering pixilation technology obsolete,[23] or that a profile photo on the web could expose your identity to complete strangers who snapped a shot of you on their phone.[24] In the age of Snowden and WikiLeaks, the aversion to both government surveillance and profiling by private for-profit organisations is therefore perfectly reasonable. However, we are often faced with a trade-off between our desire for greater privacy and our demand for smarter technology. We want personalised content and services but are annoyed by companies pushing unsolicited, targeted advertising. We want government intelligence to uncover terrorists but object to our own activities being monitored. We want our doctors to have all the knowledge in the world when treating us, and yet feel uneasy about them sharing our medical records, a contradiction again confirmed when the UK’s National Health Service (NHS) received criticism recently for giving Google DeepMind access to a large database of patient records. As is with the issue of algorithmic discrimination, there is no clear-cut solution to these problems and stakeholders need to find a balance between conflicting objectives.
For the part of tech companies and researchers, resources are being directed to finding technical solutions that enable machine learning and big data to be utilised without breaching privacy regulations. One anonymization method is known as differential privacy which, by adding random “mathematical noise” to the data, allows for the extraction of meaningful patterns on a collective basis while making it impossible to deduce the characteristics of any individual.[25] But this technique cannot fully eliminate the trade-off between accuracy and the extent of personal information “leakage”, which is not ideal when used for purposes where accuracy needs to be maximised. Homomorphic encryption is another type of encryption technology. It allows computations to be done on encrypted data without decrypting it and researchers at Microsoft have devised a system to apply this technique to neural networks.[26] Known as CryptoNets, these algorithms allows organisations to send sensitive data (e.g. medical records, tax files) in an encrypted form to a cloud service that hosts neural nets, have the neural net model applied to the encrypted data to find patterns and perform the requested task (e.g. making predictions or classifications), and then return the results in an encrypted form while keeping the data confidential from the cloud platform throughout the entire process (since the cloud platform does not have access to the decryption keys).[27] Elsewhere at Cornell Tech a group of researchers are working on a “privacy-preserving deep learning” technique that aims to enable multiple organisations to combine the key parameters from learning algorithms respectively trained on their own data to achieve results that are on par with the effect of combining their data.[28] If successful, the technology will allow hospitals and other organisations with data sharing restrictions to pool their data resources together to improve the performance of deep learning models without disclosing the restricted data.
While these technical efforts to observe privacy rules are commendable, it is perhaps also time for policymakers to consider relaxing privacy rules in some areas and allow more data sharing in order to facilitate collaborative and inclusive research as well as encourage healthy competition. The question whether DeepMind should be given free access to publicly funded and held datasets is a fair one. However, rather than denying DeepMind access because it is ultimately a for-profit enterprise and has a commercial interest, perhaps what should happen is to make the same datasets available to more researchers and somewhat level the playing field.
In this new era of machine learning, data has become a special kind of capital that is as important as physical assets and traditional intellectual property, and being in a position to collect and control unique large datasets from consumers already gives incumbent platform owners like Apple, Facebook and Google a huge advantage over newcomers. As mentioned in Part 2 of this series, IBM has been amassing medical data to fuel its AI development through both partnerships and outright acquisitions, having now gained access to 300 million patient records. There are many arguments to be made against companies treating user-generated data as their proprietary resources. However, a radical change in the law to democratise the ownership of data compiled by private as well as public organisations seems unlikely in the foreseeable future. In the absence of such reform, democratising access to public data repositories provides a key policy measure to counteract some of the impact of data-hoarding by big corporates. This is particularly important in areas such as healthcare and education where significant data are controlled by public institutions. Of course, access to data needs to have the appropriate conditions attached, such as being used for a legitimate research purpose and having reasonable anonymization and security measures.
The need to protect sensitive personal information certainly cannot be ignored. However, with the appropriate safeguards, making more datasets available to more researchers and interest groups is arguably in the public’s interest. Ultimately, policies will shift with changing public expectations. If consumers are willing to accept the likes of Apple and Google collecting their health information through their smartphones and watches, they may also become more comfortable with giving more companies access to their medical records, and the next public-private data sharing agreement may not cause so much consternation.
Intelligent Machines and the Future of Jobs
As President Obama suggested in a recent interview,[29] rather than worrying about the great “singularity” and other relatively far-fetched threats of AI, most ordinary people view the threat to their jobs as the most imminent concern with automation and cognitive computing technology. We have seen assembly line and warehouse jobs disappear as the automation of repetitive manual tasks accelerates with falling costs for industrial robots – payback period has lowered to 1.7 years for the most popular robot used in automobile production in China and less than six months in metal manufacturing in Germany.[30] Low-to-middle-skilled white collar occupations (e.g. bookkeepers and legal clerks) have also been facing growing pressure as software products computerise more and more routine information processing tasks. And now, machine learning is encroaching on yet another wave of jobs – drivers, call centre operators, translators, even reporters. Recent breakthroughs in cognitive computing, coupled with the trend towards automation over the past decades, have triggered some alarming predictions as suddenly no human occupation seems immune from machine displacement. Some studies estimate that half of all current jobs are at the risk of becoming “automated out of existence” in the next decade or two, leading to permanent unemployment on a massive scale.[31]
Techno-optimists like Tom Davenport and Julia Kirby, the authors of Only Humans Need Apply, see this bleak outlook as unrealistic and stress that augmentation – not automation – is the future. They believe that rather than making humans redundant, robots and cognitive computing will supplement human capabilities, resulting in higher productivity and greater innovation. The optimists argue that, firstly, automation is a gradual process. While machines are evidently surpassing humans at more than just number crunching and heavy lifting, they are still mostly focused on narrow domains and lack the general intelligence to perform many of the most basic functions undertaken by humans. Secondly, even if artificial general intelligence reaches a level close to human intelligence, which will be at least several decades away, machines will never completely replace human agents and will require human oversight for, for example, managing bias and ensuring accountability. Thirdly, they argue that new industries and new jobs will be created as the demands for new goods and services emerge with rising living standards and improving technology.
The speed and extent of displacement will certainly vary across sectors, depending on the nature of the occupation. According to researchers at Citi and the Oxford Martin School, the skillsets that are more resistant to automation are originality, service orientation, manual dexterity, and gross body coordination.[32] Jobs that require a great deal of sensorimotor skills (e.g. dentists and barbers) or involve complex interpersonal and communication skills may be out of machines’ reach for some time.[33] The generation of creative ideas will continue to be a quintessentially human mission, whether it is in science, business or the arts. While intelligent algorithms will play an increasingly important role in the pursuit of all natural and social sciences and cognitive computing is already changing how many services are delivered (e.g. healthcare, business analytics, fraud detection), these are expected to be collaborations, not displacement. With the more artistic endeavours, while computer algorithms are trying out screenwriting,[34] even poetry,[35] and are venturing into painting and jazz composition,[36] they are likely to supplement human creativity, rather than become a substitute for our own imagination.
But all this is of little comfort to the poor cabbies and truck drivers facing the prospect of losing their livelihoods to autonomous cars, trucks and drones. The real cause for concern is the widening gap in skillset and adaptability. Tech entrepreneurs and computer scientists will reap great rewards from the opportunities brought about by the onset of AI and other highly-educated professionals may also survive by upskilling while relegating the more mundane parts of their work to machines, but low-skilled workers with little intellectual and financial capital fear being left further and further behind. Economist Erik Brynjolfsson and scientist Andrew McAfee argue that the rate of technological change in the digital information age, which they term the “Second Machine Age”, is “of a different order to the Industrial Revolution”, entailing change on a similar scale overall, but at a much faster rate.[37] The worry is that there won’t be time for society to adjust over several generations and many of those in the current workforce with specialised roles will have little opportunity to retrain and adapt before being replaced by cheaper, faster and more consistent machine alternatives.
The associated deep concern is one of growing wealth inequality. Since the turn of the 21st Century, labour’s share as a percentage of GDP in the US has been declining while capital’s share more than doubled, and while labour productivity continued to rise, job creation did not keep up. Moreover, real median income has stagnated while productivity continues to grow, evidencing that “the benefits of technological change are not being widely shared”.[38] The current populist movement, as embodied by the UK’s Brexit vote and Trump’s win in the US presidential election, is testimony to the disgruntlement of the middle and lower classes of developed countries who are bearing the brunt of the negative ramifications of both technological progress and globalisation. As one commentator summed up, “The root of the problem is structural: the educational system has not kept up with technological change and as a result there is an excess supply of unskilled labour.”[39]
In response to these threats of economic disruption by automation and machine intelligence, some are calling for major policy reform in the direction of adopting a universal basic income (UBI) scheme, meaning that every citizen will be unconditionally guaranteed by the government to receive an income that will meet their most basic needs. Several countries, including Finland, Canada and the Netherlands, are putting the idea to trial.[40] The proponents of UBI argue that it enables more equitable wealth re-distribution and, compared with existing minimum wage laws, it would place less direct onus on employers and businesses, hence would be less damaging to economic growth. They also generally believe – or assume – that AI and other technological leaps will deliver huge productivity gains and raise society’s collective wealth while the abolition of existing ragbags of welfare programs will help to pay for a universal basic income. Critics, however, argue that, besides the problem of affordability, a guaranteed basic income cannot fulfil people’s innate needs for a sense of purpose and accomplishment; it cannot replace work as a source of meaning and identity. Whether or not UBI is the solution, the rapid development of automation and machine intelligence is compelling us to develop new economic models and social institutions to ensure that the productivity gains from AI are applied towards ameliorating living standards for all and that the fruits of technology are being shared widely.
Braving a New World
Some call this a Cambrian moment. Some see it as opening Pandora’s Box. Whatever the metaphor, the very reasons that deep learning and the prospect of creating AGI have ignited so much excitement are also causes for concern. The ability of a computer algorithm to independently acquire knowledge and solve problems, including the ability to modify itself and generate new algorithms, carries enormous destructive potential. The more extreme version of the dystopian view expresses an existential fear that artificial superintelligence (ASI), the name given to machines endowed with “a general intelligence that vastly outperforms the best human brains in every significant cognitive domain”,[41] might spell human extermination if we fail to ensure that their goals and desires are aligned with ours, the kind of insidious act embodied by HAL 9000 from 2001: A Space Odyssey. A more moderate version conjures up a scenario where an intelligent machine sets out to accomplish a goal set by humans, but inadvertently brings about disastrous consequences due to its single-mindedness at achieving that goal and total oblivion to all other considerations. Philosopher Nick Bostrom’s hypothetical paper clip-maximising super machine is an oft-cited example, as is the human-stamping-on-ants analogy given by the venerable Stephen Hawking.
While such apocalyptic pronouncements help to raise awareness about the importance of deeper, multi-disciplinary AI research, many at the forefront of this Promethean undertaking, such as Demis Hassabis (co-founder of DeepMind), Andrew Ng (Chief Scientist at Baidu and former head of Google Brain) and Yann LeCun (Director of Facebook AI Research), seem to be far less pessimistic. AI algorithms are mathematical equations written by humans; their goals are defined by humans and their autonomy given by humans. Even the most advanced ASI will not have the biological drive to survive and reproduce or the genetic instincts to compete for resources, unless, of course, we encode these genes into them. So half of the challenge is about human competence – whether we can get the maths right. As for contingencies, by most experts’ account, we have at least several decades to perfect “kill-switch” codes and other measures to keep AI in check.[42] The other half is about human motivation. Misuse of machine intelligence may indeed pose existential threats to humanity – assassinations may become a matter of hacking into a self-driving car or deploying a wasp-sized drone.[43] But this is not unique to AI technology, and the threat of nuclear weapons has provided more than a precedent to reflect on.
Machine intelligence is a tool, an increasingly powerful tool, but the control of which ultimately rests with humans, as does the responsibility. It is up to us to ensure that AI warfare and ASI hegemony are kept to the realm of science fiction, and that the might of machine intelligence, like all technology, is harnessed to empower and enrich humanity as a whole. This will be the ultimate test of human intelligence.
DISCLAIMER: The above information is commentary only (i.e. our general thoughts). It is not intended to be, nor should it be construed as, investment advice. To the extent permitted by law, no liability is accepted for any loss or damage as a result of any reliance on this information. Before making any investment decision you need to consider (with your financial adviser) your particular investment needs, objectives and circumstances. The above material may not be reproduced, in whole or in part, without the prior written consent of Platinum Investment Management Limited.
From the journal

Lessons with an investment professional - nine more tips
Douglas Isles' tips explore the hidden dangers of a headline and the power of quality.

Investment lessons with a pro - the front nine
Doug Isles draws on 18 years' experience to talk cliches, hype and the perils of past performance

Scottie Scheffler and the ‘happy amateur’ investor
What can investors learn from the distinction between amateur and professional sport?

It’s a living thing – investing in biologics
Adrian Cotiga explains the rationale behind Platinum's investment in biologics company Lonza.
Subscribe to Platinum
Receive our expert investment insights and market updates.
Journal Articles
Read market leading insights.
Market Updates
Get market updates from our analysts
Quarterly Reports
Receive quarterly investment reports